spotify_all <- read_csv('https://bcdanl.github.io/data/spotify_all.csv')Let’s analyze the spotify_all data:
The data.frame spotify_all includes information about Spotify users’ playlists.
- The unit of observation in
spotify_allis a track in a music playlist.
Variable Description
pid: playlist ID; unique ID for playlistplaylist_name: a name of playlistpos: a position of the track within a playlist (starting from 0)artist_name: name of the track’s primary artisttrack_name: name of the trackduration_ms: duration of the track in millisecondsalbum_name: name of the track’s album
The Top 10 Popular Artist, and Their Position on Spotify Playlists
top10_artist <- spotify_all |>
select(artist_name) |>
count(artist_name) |>
slice_max(n, n = 10)
top10_artist_and_pos <- spotify_all |>
filter(artist_name %in% top10_artist$artist_name)
ggplot(top10_artist_and_pos,
aes(x = pos)) +
geom_histogram()+
facet_grid(artist_name ~ .)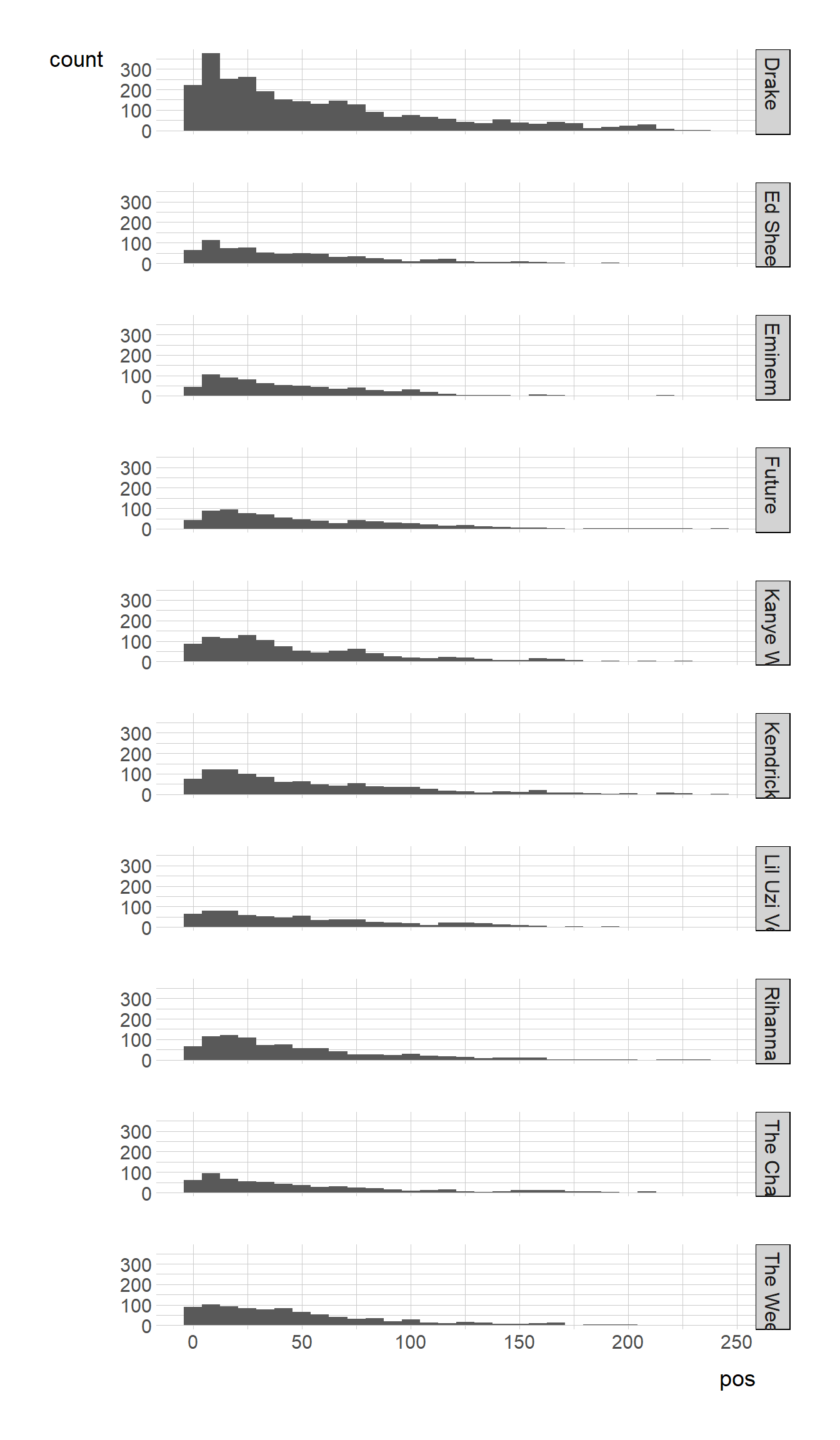
#Most of the top 10 artist’s songs are positioned in the first 50 songs in a playlist, and Drake in particular has most of his songs positioned in the first 25 songs of the playlists we observed. This could also be because he has the most songs out of any of the top 10 artists.